Course: Hadoop Ecosystem
duration: 29 hours |
Language: English (US) |
access duration: 90 days |

Details
In this Hadoop training course you will learn about the Hadoop ecosystem. Thus, the most common open source components are covered, but you will also learn to install Hadoop. Later in the course, data repository (HDFS, Flume, Sqoop) and datafactory (Hive, Pig, Oozie) is discussed.
Among the topics covered are repository components, YARN, HDFS, Name Node and Data Node, Flume, MySQL, Java API MapReduce, Hive, Pig, Oozie and far more.
Result
After completing this training course you are familiar with the entire ecosystem of Hadoop and you know how to install it.
Prerequisites
There are no specific requirements.
Target audience
Network Administrator, Software Developer, Database Administrators
Content
Hadoop Ecosystem
Ecosystem for Hadoop
- start the course
- describe supercomputing
- recall three major functions of data analytics
- define Big Data
- describe the two different types of data
- describe the components of the Big Data stack
- identify the data repository components
- identify the data refinery components
- identify the data factory components
- recall the design principles of Hadoop
- describe the design principles of sharing nothing
- describe the design principles of embracing failure
- describe the components of the Hadoop Distributed File System (HDFS)
- describe the four main HDFS daemons
- describe Hadoop YARN
- describe the roles of the Resource Manager daemon
- describe the YARN NodeManager and ApplicationMaster daemons
- define MapReduce and describe its relations to YARN
- describe data analytics
- describe the reasons for the complexities of the Hadoop Ecosystem
- describe the components of the Hadoop ecosystem
Installation of Hadoop
- start the course
- recall the minimum system requirements for installation
- configure the start-up shell and yum repositories
- install the Java Developers Kit
- setup SSH for Hadoop
- recall why version 2.0 was significant
- describe the three different installation modes
- download and install Apache Hadoop
- configure Hadoop environmental variables
- configure Hadoop HDFS
- start and stop Hadoop HDFS
- configure Hadoop YARN and MapReduce
- start and stop Hadoop YARN
- validate the installation and configuration
- recall the structure of the HDFS command
- recall the importance of the output directory
- run WordCount
- recall the ports of the NameNode and Resource Manager Web UIs
- use the NameNode and Resource Manager Web UIs
- describe the best practices for changing configuration files
- recall some of the most common errors and how to fix them
- access Hadoop logs and troubleshoot Hadoop installation errors
- to install and configure Hadoop and its associated components
Data Repository with HDFS and HBase
- start the course
- configure the replication of data blocks
- configure the default file system scheme and authority
- describe the functions of the NameNode
- recall how the NameNode operates
- recall how the DataNode maintains data integrity
- describe the purpose of the CheckPoint Node
- describe the role of the Backup Node
- recall the syntax of the file system shell commands
- use shell commands to manage files
- use shell commands to provide information about the file system
- perform common administration functions
- configure parameters for NameNode and DataNode
- troubleshoot HDFS errors
- describe key attributes of NoSQL databases
- describe the roles of HBase and ZooKeeper
- install and configure ZooKeeper
- instause the HBase command line to create tables and insert datall and configure HBase
- instause the HBase command line to create tables and insert datall and configure HBase
- manage tables and view the web interface
- create and change HBase data
- provide a basic understanding of how Hadoop Distributed File System functions
Data Repository with Flume
- start the course
- describe the three key attributes of Flume
- recall some of the protocols cURL supports
- use cURL to download web server data
- recall some best practices for the Agent Conf files
- install and configure Flume
- create a Flume agent
- describe a flume agent in detail
- use a flume agent to load data into HDFS
- identify popular sources
- identify popular sinks
- describe Flume channels
- describe what is happening during a file roll
- recall that Avro can be used as both a sink and a source
- use Avro to capture a remote file
- create multiple-hop Flume agents
- describe interceptors
- create a Flume agent with a TimeStampInterceptor
- describe multifunction Flume agents
- configure Flume agents for mutliflow
- create multi-source Flume agents
- compare replicating to multiplexing
- create a Flume agent for multiple data sinks
- recall some common reasons for Flume failures
- use the logger to troubleshoot Flume agents
- configure the various Flume agents
Data Repository with Sqoop
- start the course
- describe MySQL
- install MySQL
- create a database in MySQL
- create MySQL tables and load data
- describe Sqoop
- describe Sqoop's architecture
- recall the dependencies for Sqoop installation
- install Sqoop
- recall why it's important for the primary key to be numeric
- perform a Sqoop import from MySQL into HDFS
- recall what concerns the developers should be aware of
- perform a Sqoop export from HDFS into MySQL
- recall that you must execute a Sqoop import statement for each data element
- perform a Sqoop import from MySQL into HBase
- recall how to use chain troubleshooting to resolve Sqoop issues
- use the log files to identify common Sqoop errors and their resolutions
- to use Sqoop to extract data from a RDBMS and load the data into HDFS
Data Refinery with YARN and MapReduce
- start the course
- describe parallel processing in the context of supercomputing
- list the components of YARN and identify their primary functions
- diagram YARN Resource Manager and identify its key components
- diagram YARN Node Manager and identify its key components
- diagram YARN ApplicationMaster and identify its key components
- describe the operations of YARN
- identify the standard configuration parameters to be changed for YARN
- define the principle concepts of key-value pairs and list the rules for key-value pairs
- describe how MapReduce transforms key-value pairs
- load a large text book and then run WordCount to count the number of words in the text book
- label all of the functions for MapReduce on a diagram
- match the phases of MapReduce to their definitions
- set up the classpath and test WordCount
- build a JAR file and run WordCount
- describe the base mapper class of the MapReduce Java API and describe how to override its methods
- describe the base Reducer class of the MapReduce Java API and describe how to override its methods
- describe the function of the MapReduceDriver Java class
- set up the classpath and test a MapReduce job
- identify the concept of streaming for MapReduce
- stream a Python job
- understand YARN features and components, as well as MapReduce and its classes
Data Factory with Hive
- start the course
- recall the key attributes of Hive
- describe the configuration files
- install and configure Hive
- create a table in Derby using Hive
- create a table in MySQL using Hive
- recall the unique delimiter that Hive uses
- describe the different operators in Hive
- use basic SQL commands in Hive
- use SELECT statements in Hive
- use more complex HiveQL
- write and use Hive scripts
- recall what types of joins Hive can support
- use Hive to perform joins
- recall that a Hive partition schema must be created before loading the data
- write a Hive partition script
- recall how buckets are used to improve performance
- create Hive buckets
- recall some best practices for user defined functions
- create a user defined function for Hive
- recall the standard error code ranges and what they mean
- use a Hive explain plan
- understand configuration option, data loading and querying
Data Factory with Pig
- start the course
- describe Pig and its strengths
- recall the minimal edits needed to be made to the configuration file
- install and configure Pig
- recall the complex data types used by Pig
- recall some of the relational operators used by Pig
- use the Grunt shell with Pig Latin
- set parameters from both a text file and with the command line
- write a Pig script
- use a Pig script to filter data
- use the FOREACH operator with a Pig script
- set parameters and arguments in a Pig script
- write a Pig script to count data
- perform data joins using a Pig script
- group data using a Pig script
- cogroup data with a Pig script
- flatten data using a pig script
- recall the languages that can be used to write user defined functions
- create a user defined function for Pig
- recall the different types of error categories
- use explain in a Pig script
- install Pig, use Pig operators and Pig Latin, and retrieve and group records
Data Factory with Oozie and Hue
- start the course
- describe metastore and hiveserver2
- install and configure metastore
- install and configure HiveServer2
- describe HCatalog
- install and configure WebHCat
- use HCatalog to flow data
- recall the Oozie terminology
- recall the two categories of environmental variables for configuring Oozie
- install Oozie
- configure Oozie
- configure Oozie to use MySQL
- enable the Oozie Web Console
- describe Oozie workflows
- submit an Oozie workflow job
- create an Oozie workflow
- run an Oozie workflow job
- describe Hue
- recall the configuration files that must be edited
- install Hue
- configure the hue.ini file
- install and configure Hue on MySQL
- use the Hue File Browser and Job Scheduler
- configure Hive daemons, Oozie, and Hue
Data Flow for the Hadoop Ecosystem
- start the course
- describe the data life cycle management
- recall the parameters that must be set in the Sqoop import statement
- create a table and load data into MySQL
- use Sqoop to import data into Hive
- recall the parameters that must be set in the Sqoop export statement
- use Sqoop to export data from Hive
- recall the three most common date datatypes and which systems support each
- use casting to import datetime stamps into Hive
- export datetime stamps from Hive into MySQL
- describe dirty data and how it should be preprocessed
- use Hive to create tables outside the warehouse
- use pig to sample data
- recall some other popular components for the Hadoop Ecosystem
- recall some best practices for pseudo-mode implementation
- write custom scripts to assist with administrative tasks
- troubleshoot classpath errors
- create complex configuration files
- to use Sqoop and Hive for data flow and fusion in the Hadoop ecosystem
Course options
We offer several optional training products to enhance your learning experience. If you are planning to use our training course in preperation for an official exam then whe highly recommend using these optional training products to ensure an optimal learning experience. Sometimes there is only a practice exam or/and practice lab available.
Optional practice exam (trial exam)
To supplement this training course you may add a special practice exam. This practice exam comprises a number of trial exams which are very similar to the real exam, both in terms of form and content. This is the ultimate way to test whether you are ready for the exam.
Optional practice lab
To supplement this training course you may add a special practice lab. You perform the tasks on real hardware and/or software applicable to your Lab. The labs are fully hosted in our cloud. The only thing you need to use our practice labs is a web browser. In the LiveLab environment you will find exercises which you can start immediately. The lab enviromentconsist of complete networks containing for example, clients, servers,etc. This is the ultimate way to gain extensive hands-on experience.
Sign In
WHY_ICTTRAININGEN
Betaal in termijnen
| Cursusnaam | |
| Looptijd | |
| Rentebedrag financiering | |
| Totaal bedrag | |
| Maandbedrag |

Gespreid betalen met Spraypay
Met de betaaloptie SprayPay kun je jouw bestelling van € 250,- tot € 3.500,- veilig en gespreid betalen in gelijke termijnen van 12, 18, 24 of 36 maanden. Je hebt op die manier een minimale financiële belasting en je kunt eenvoudig de termijnbetalingen opnemen in jouw vaste lasten.
Hoe werkt het kopen op afbetaling? De beoordeling van de kredietaanvraag vindt online plaats. Binnen enkele seconden weet je of je in aanmerking komt voor een krediet. Is de aanvraag akkoord dan kun je meteen genieten van je aankoop.
Let op: deze betaalmetode is aleen beschikbaar voor particulieren! Bekijk voor je aankoop ook de SprayPay voorwaarden.

Via ons opleidingsconcept bespaar je tot 80% op trainingen
Start met leren wanneer je wilt. Je bepaalt zelf het gewenste tempo
Spar met medecursisten en profileer je als autoriteit in je vakgebied.
Ontvang na succesvolle afronding van je cursus het officiële certificaat van deelname van Icttrainingen.nl
Krijg inzicht in uitgebreide voortgangsinformatie van jezelf of je medewerkers
Kennis opdoen met interactieve e-learning en uitgebreide praktijkopdrachten door gecertificeerde docenten
Orderproces
Once we have processed your order and payment, we will give you access to your courses. If you still have any questions about our ordering process, please refer to the button below.
read more about the order process
Een zakelijk account aanmaken
Wanneer u besteld namens uw bedrijf doet u er goed aan om aan zakelijk account bij ons aan te maken. Tijdens het registratieproces kunt u hiervoor kiezen. U heeft vervolgens de mogelijkheden om de bedrijfsgegevens in te voeren, een referentie en een afwijkend factuuradres toe te voegen.
Betaalmogelijkheden
U heeft bij ons diverse betaalmogelijkheden. Bij alle betaalopties ontvangt u sowieso een factuur na de bestelling. Gaat uw werkgever betalen, dan kiest u voor betaling per factuur.

Cursisten aanmaken
Als u een zakelijk account heeft aangemaakt dan heeft u de optie om cursisten/medewerkers aan te maken onder uw account. Als u dus meerdere trainingen koopt, kunt u cursisten aanmaken en deze vervolgens uitdelen aan uw collega’s. De cursisten krijgen een e-mail met inloggegevens wanneer zij worden aangemaakt en wanneer zij een training hebben gekregen.
Voortgangsinformatie
Met een zakelijk account bent u automatisch beheerder van uw organisatie en kunt u naast cursisten ook managers aanmaken. Beheerders en managers kunnen tevens voortgang inzien van alle cursisten binnen uw organisatie.
What is included?
| Certificate of participation | Yes |
| Monitor Progress | Yes |
| Award Winning E-learning | Yes |
| Mobile ready | Yes |
| Sharing knowledge | Unlimited access to our IT professionals community |
| Study advice | Our consultants are here for you to advice about your study career and options |
| Study materials | Certified teachers with in depth knowledge about the subject. |
| Service | World's best service |
Platform
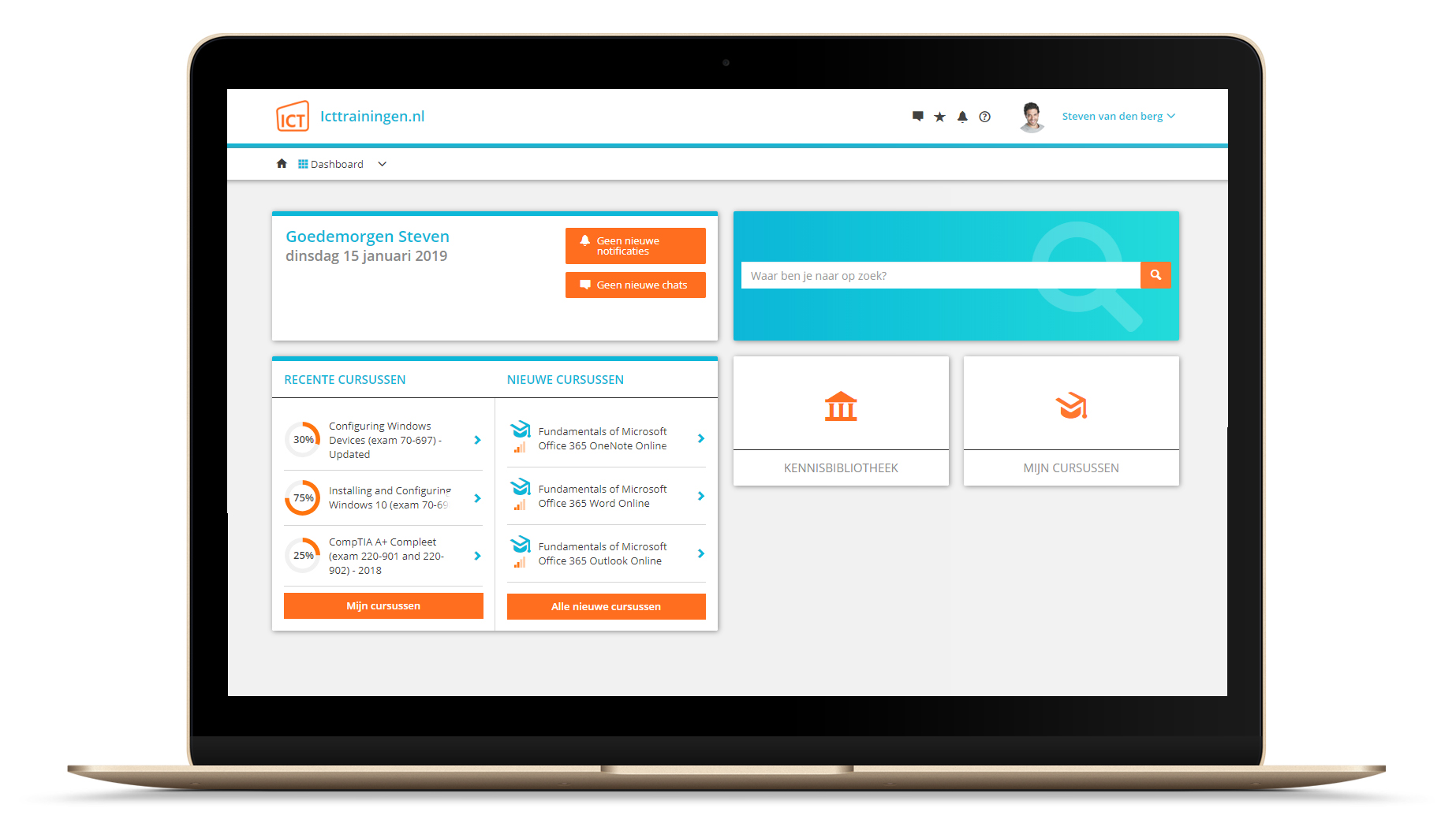
Na bestelling van je training krijg je toegang tot ons innovatieve leerplatform. Hier vind je al je gekochte (of gevolgde) trainingen, kan je eventueel cursisten aanmaken en krijg je toegang tot uitgebreide voortgangsinformatie.
FAQ
Niet gevonden wat je zocht? Bekijk alle vragen of neem contact op.